Problem
Chicago is home to fantastic independent cinemas and many eager moviegoers. But these venues and their audiences are separated by several digital gaps:
- Major moviegoing platforms like Fandango rarely include listings from Chicago’s independent cinemas, placing them outside the planning tools that many rely on for movie nights
- Showtimes and critic reviews live on separate sites, splitting the discovery process across multiple tabs and slowing it
- Deciding between films, venues, or dates requires hopping between different lists of showtimes, typically without common filters, sorting, or structure
- Traditional showtime listings reduce screenings to isolated text rows, making their duration and overlap hard to see at a glance
Taken together, these frictions make Chicago’s indie film landscape harder to explore than it should be. Moviegoers deserve a clearer, more unified way through it. And the cinemas at its center deserve digital representation that honors their contribution.
Goals
My vision of a unified indie moviegoing platform didn’t arrive as a sudden insight, nor as a neatly defined specification. It developed gradually out of organizing countless cinema outings, both with friends and through Meetup. Over time, the friction points faced by modern moviegoers became unmistakable, and a clearer sense emerged of what was needed in a digital tool.
From those accumulated experiences, the project’s goals solidified along two dimensions: the product experience I wanted to offer, and the engineering foundation required to make it reliable, extensible, and automated.
Product Goals
- Create a single, authoritative view of Chicago’s indie film landscape by consolidating showtimes from multiple venues.
- Reduce friction in discovery by pairing showtimes with critic reviews, both individual and aggregated, in one environment.
- Improve navigability with intuitive, interactive views and consistent filtering across calendar and critic-review components.
- Provide decision-making clarity through consolidated critic reviews, rich event context, and visual cues that reveal how screenings relate in time.
Engineering Goals
- Automate nightly ingestion via robust scrapers and a unified ETL pipeline.
- Normalize data at ingestion, isolating venue-specific inconsistencies and ensuring reliable downstream behavior.
- Design for extensibility, allowing new data sources (Letterboxd, additional cinemas, film-poster assets) to slot naturally into the pipeline.
- Deliver a dense-but-legible frontend, built to present substantial amounts of information while preserving clarity, intuitive control, and responsiveness across devices.
- Prepare for advanced analysis, including predictive modeling of theatrical run lengths and longitudinal studies of review scores.
Aiming for these goals helps ensure that The Indie Cini’s screening data is rigorously accurate, continuously updated, richly contextualized, and intuitively accessible. These priorities continue to guide the app’s evolution.
They anchor future work such as incorporating additional indie venues, expanding review and metadata sources, adding poster imagery, and refining the calendar views. And as the underlying dataset grows, so too does the potential for analytic extensions, like modeling theatrical run lengths, offering deeper insight into how films circulate through the city’s indie cinemas.
Architecture
Overview
The Indie Cini is a modular, end-to-end pipeline that automates data collection, shapes a consistent internal schema from varied venue and review sources, and delivers it to a responsive browser interface. The system separates scraping, ingestion, storage, transformation, and presentation into distinct conceptual layers, allowing each part to evolve independently while maintaining a predictable flow of data from external sites to the frontend.
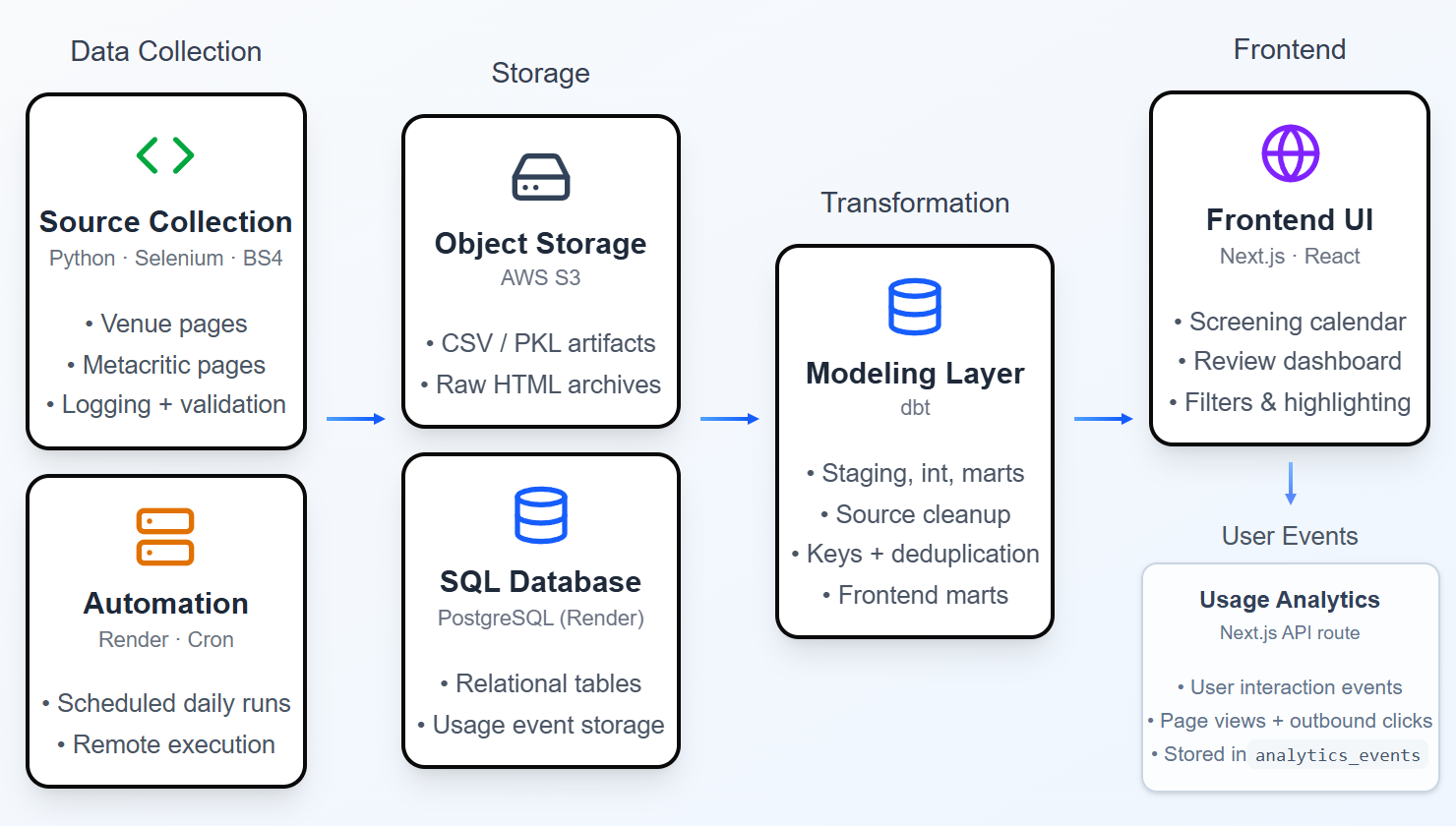
Nightly Selenium scrapers— supported by a fault-tolerant rotating driver— collect showtimes, film details, and critic reviews, applying normalization to reconcile source-specific formatting inconsistencies. These structured outputs are written to S3 as timestamped artifacts, checked through lightweight inventory and quality reports, and then ingested into PostgreSQL, the system’s canonical, current-state warehouse.
From there, a dedicated transformation layer built with dbt reshapes the ingested tables into structured analytical models. This layer organizes data across staging, intermediate, and mart tiers, constructing stable join keys, deduplicating review data, and producing feature-specific datasets that power the application’s frontend.
A Next.js frontend consumes these modeled datasets through lightweight API routes and renders them via interactive calendar and review-exploration components. In parallel, a lightweight analytics system captures user interaction events from the frontend, storing them in a persistent event table for downstream analysis.
This layered design makes the platform reliable in operation and flexible in extension as new venues, metadata sources, or interface features are introduced.
Scraping
To parse data from a range of online sources, The Indie Cini deploys an array of custom scrapers. Each scraper adapts to a site’s unique structure, quirks, and inconsistencies—patterns that vary across venues and shift over time.
Despite these differences, all scrapers share a robust core: a fault-tolerant, memory-aware Selenium driver that restarts itself when stalled. With this RotatingDriver, the scrapers can reliably navigate JavaScript-heavy pages, and execute targeted page-interaction scripts to reveal content unrendered by default. These interactions allow the scrapers to access data that would otherwise remain inaccessible.
The scraping process runs nightly and proceeds in two phases: venues first, reviewers second. The venue scraping phase retrieves showtimes, film metadata, and selected source HTML. These fields are normalized and validated at the time of scraping, formed into structured DataFrames, and saved to S3 as pickled DataFrames and HTML snapshots.
This freshly written metadata then seeds the review scraping phase. For each film, the review scraper searches for the corresponding Metacritic page by iterating over a subset of its identifying fields and applying an empirically tuned relevance ranking. To reduce the expense of this operation, the scraper maintains persistent master files of previous searches and their outcomes. Finally, as with the venue data, the scraped reviews are normalized, validated, and saved to S3 as pickled DataFrames.
Observability
The observability layer is responsible for inspecting these scrape artifacts as first-class pipeline outputs. It operates after venue and Metacritic artifact generation and before warehouse loading, producing two timestamped report types: an inventory report for artifact presence and freshness, and a quality report for structural checks and entity-level findings. Together, these reports give the pipeline a dedicated checkpoint for identifying stale, missing, malformed, or otherwise notable artifacts before they affect downstream tables or application-facing models.
The inventory report tracks the latest available file for each scrape source and artifact type, recording its artifact date and whether it appears current, stale, or missing relative to the rest of the run. The quality report inspects the contents of each latest artifact and produces both summary-level metrics and entity-level findings, including checks for duplicate film identifiers, missing values, invalid runtimes or review scores, unmatched Metacritic searches, and artifact-specific volume patterns such as reviews or showtimes per film.
Each report row includes provenance metadata such as scrape source, artifact type, artifact path, artifact date, and observation timestamp. This distinction matters because the system checks the latest available artifact for each source-type combination, and those artifacts may not all come from the same scrape date.
By making artifact freshness and structural quality explicit, the observability layer gives the project a clearer feedback loop around the intermediate files that feed the warehouse and frontend.
Ingestion
After each nightly scrape, the ingestion layer processes the latest showtime, metadata, and review datasets produced by the scrapers. Its job is to load these artifacts into the structured tables that drive the rest of the system.
It reads the scraped DataFrames through a custom StorageBackend interface. Those datasets are then checked for basic health before normalization. Their fields are lightly normalized by standardizing names, casting values where needed, and aligning them with the database’s expected column types.
The loaders then use SQLAlchemy to overwrite the existing tables with the latest scrape, thereby enforcing a predictable and deterministic update cycle. The same ingestion logic supports both development and production: it can read from S3 or local disk and write into PostgreSQL or a local MySQL instance. By consistently refreshing the core tables that feed the SQL views, the ingestion layer keeps the frontend accurate and up to date.
Storage
Scraping and ingestion do not exchange data directly; instead, they meet at the storage layer. The storage layer ensures that scraped artifacts are durably saved and organized into clear, run-based directories.
This design gives the system consistency and reproducibility—qualities that make debugging easier, support retrospective analysis, and help preserve data integrity. These goals are supported by two core mechanisms: the unified StorageBackend interface and a centralized pathing.py module that defines directory and filename conventions.
The StorageBackend Abstraction
At the center of the storage layer is the StorageBackend abstraction, which provides a unified interface for reading and writing scraped artifacts regardless of their physical location. Whether the system is running locally or in production on S3, the scrapers and loaders interact with data through the same set of methods.
This keeps file-I/O concerns completely separate from the scraping and ingestion logic: those components issue simple load and save calls, and the backend resolves the underlying mechanics. Because both backend implementations mirror the same interface, switching between development and production requires only a one-line configuration change rather than a code rewrite.
Pathing and Directory Structure
pathing.py centralizes all naming rules and directory conventions for the pipeline, ensuring that every scrape stores its outputs in a predictable, reproducible layout. Each run’s DataFrames are written as .pkl files under a structured hierarchy:
data/pkl/<venue-or-review-source>/<scrape-type>/<YYYY-MM-DD>.pkl
This pattern makes the storage location itself encode essential metadata — where the data came from, what type it represents, and when it was produced. The same conventions apply to HTML snapshots and other scrape artifacts, giving the storage layer a uniform shape across both local and S3 backends.
As a result, any run’s outputs can be located, interpreted, and cross-referenced without digging through code. This consistency supports reproducibility, simplifies debugging, and ensures that downstream components always know exactly where to find the inputs they depend on.
Together, the StorageBackend abstraction and the pathing.py module form the core of the storage layer. StorageBackend abstracts file I/O across local disk and S3, while pathing.py standardizes naming and organization.
In tandem, these mechanisms make reads and writes predictable and reproducible, providing a stable intermediary between the scraping and ingestion layers. By establishing a shared, programmatic contract for how data is written and later retrieved, the storage layer ensures continuity across pipeline stages, which is essential to the system’s overall integrity.
Database
The PostgreSQL database serves as the system’s canonical, query-optimized representation of the latest scrape. It is designed to hold a consistent, queryable snapshot of currently slated screenings and their associated critic reviews, rather than function as a long-term archive.
To support this role, the ingestion pipeline follows a full-refresh pattern: on each run, tables are cleared and repopulated from the latest scraped datasets. This approach simplifies ingestion logic and avoids reconciliation issues across runs, favoring consistency and correctness over incremental updates. The result is a stable foundation for downstream transformation.
In this architecture, the database does not directly shape application-facing data. Instead, it acts as the boundary between ingestion and transformation, storing normalized yet largely source-aligned tables that are then consumed by a dedicated modeling layer.
This separation clarifies the system’s data pipeline: ingestion is responsible for reliably loading structured data; the database preserves it in a consistent relational form; and transformation is handled explicitly downstream. By limiting the database’s role to canonical storage, the system avoids embedding complex business logic at the storage layer and instead enables a more modular, inspectable, and extensible transformation process.
Transformation
Data transformation in The Indie Cini is handled by a dedicated modeling layer built with dbt. It reshapes ingested tables into structured, application-facing datasets.
This modeling layer organizes transformations across staging, intermediate, and mart tiers. Staging models standardize source-specific tables that mirror individual scrape artifacts — showtimes, film details, and critic reviews — bringing them into a consistent format, while preserving their original structure.
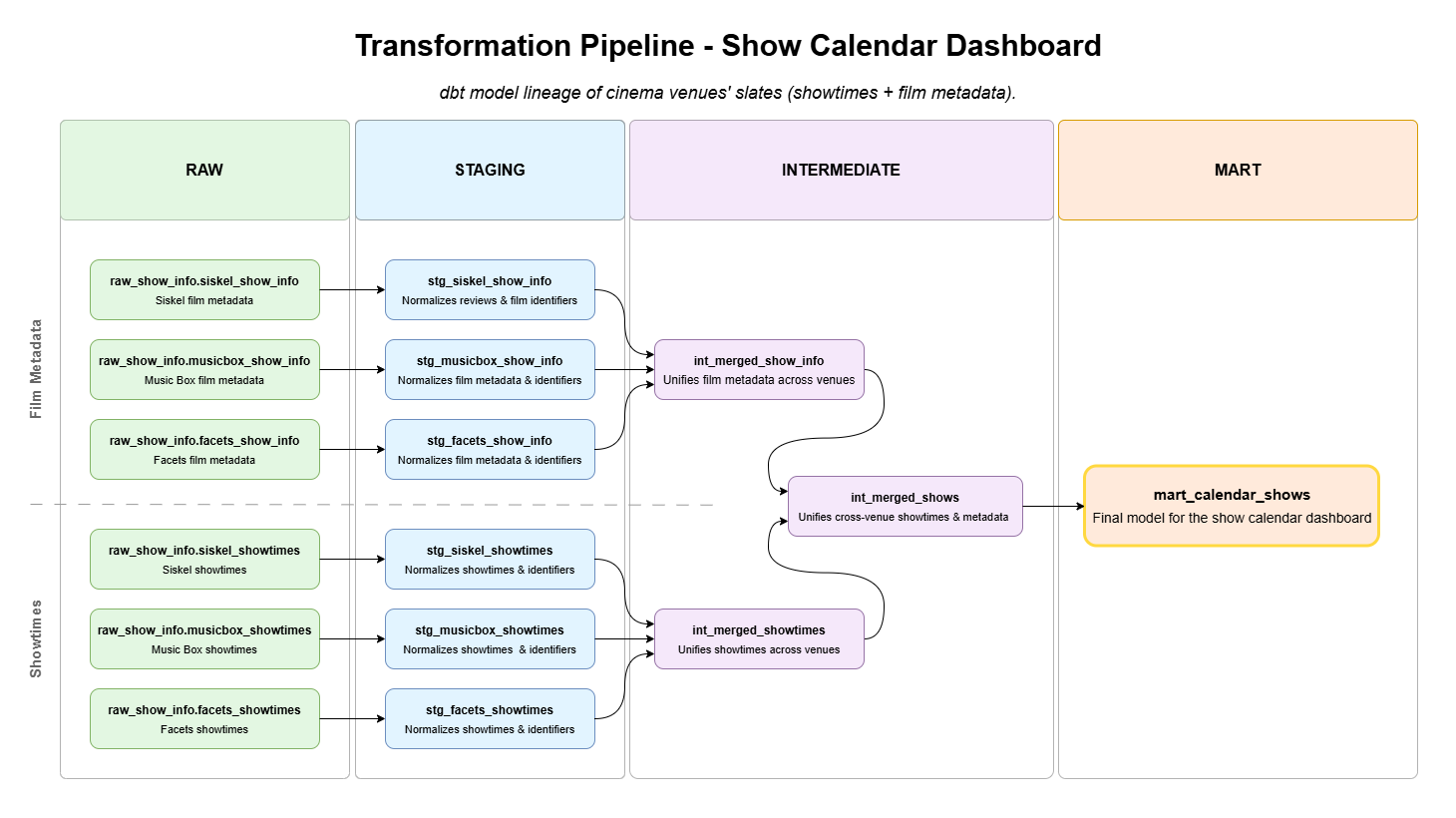
Intermediate models then perform the core relational work of the system, combining venue data into unified representations of showtimes and film metadata, and linking those screenings with their corresponding reviews. The final mart models produce feature-specific datasets that directly support the application’s interfaces, including the screening calendar and the review dashboard.
Within this structure, the modeling layer expresses transformation logic declaratively and in a modular form. It centralizes the operations required to turn heterogeneous scrape outputs into tailored datasets, while keeping each step explicit and inspectable. By formalizing those steps into sequences of well-scoped models, this layer makes the logic of its data-shaping easier to reason about, revise, and extend.
This design simplifies the frontend’s queries, establishes clear data contracts across components, and keeps semantic shaping close to the data itself. As the application evolves — whether through new venues, richer metadata, or expanded review logic — the modeling layer provides a flexible but disciplined surface for expressing how raw inputs are transformed into meaningful structures.
Review Aggregation
One transformation plays a distinct semantic role in the system: the model that prepares film reviews from multiple publications for moviegoers’ comparison, producing the dataset that powers the application’s review dashboard (`mart_review_dashboard`). By grouping reviews at the publication level rather than leaving them as individual critic entries, this transformation presents a form that is more recognizable to users and more conducive to comparative browsing.
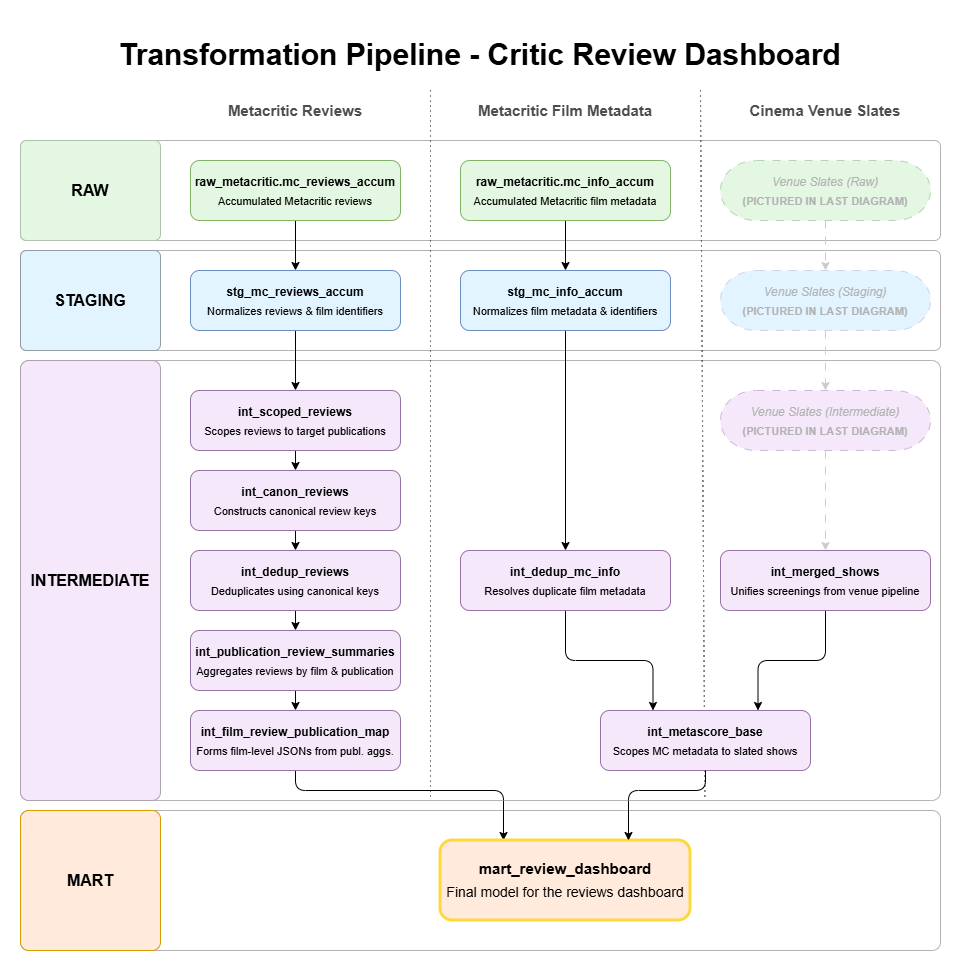
In the scraped source data, critic reviews appear as individual entries, sometimes associated with the same publication. Reconciling these many-to-one relationships requires aggregation logic that consolidates scores by publication while resolving occasional duplication.
This process performs that reconciliation by combining individual critic responses into legible review round-ups — and it does so without sacrificing voices. While scores are summarized for comparison, the constituent reviews are preserved and exposed as context, allowing the frontend to present both concise metrics and the rich commentaries underlying them.
In this way, the review transformation defines how a film’s reviews are represented to users, balancing comparative clarity with preserved critical context, and expressing that logic directly within the modeling layer rather than embedding it in the frontend.
Usage Analytics
To better understand how users interact with the application, I implemented a lightweight, event-based analytics system that captures key frontend events and stores them in a dedicated PostgreSQL table.
The system is designed around a simple API layer (`/api/analytics`) that receives structured event payloads from the frontend and writes them to an append-only `analytics_events` table. Each event includes a timestamp, event type, and a extensible metadata structure, enabling the system to capture evolving interaction patterns without requiring frequent schema changes.
Two core event types are currently tracked:
- `page_view` — logs visits to application pages, recording the URL path
- `outbound_click` — captures clicks from the calendar to official venue pages for screened films, recording the destination URL and associated screening metadata
The `outbound_click` events are particularly meaningful, as they bridge user interaction with real-world intent. These events reflect moments where users move from browsing the application to engaging with a film at its source, providing a direct signal of interest and intent.
Importantly, this analytics system operates independently of the ingestion and transformation pipeline. Unlike the core modeled datasets, which are refreshed daily via dbt, the analytics event table persists across runs and grows incrementally over time, enabling longitudinal analysis of user behavior.
This design provides a strong foundation for future analysis, such as:
- identifying high-interest films or venues
- comparing engagement across time ranges
- measuring the effectiveness of UI changes or feature additions
Together, these capabilities position the analytics layer as a foundation for continued product insight and iteration.
Frontend
The frontend is what makes The Indie Cini an usher, rather than a marquee. It forms an accessible guide of interactive dashboards from a dense dataset of screenings and reviews. Rather than transform this tailored dataset further, the frontend deliberately constrains itself to interpretation: its focus is to legibly present the canonical views that it consumes from upstream.
The frontend first offers broad overviews, allowing users to orient themselves quickly. Then as user interest narrows, it exposes additional detail through hovercards, tooltips, and interaction. In this way, the interface manages informational density as users shift between exploration and decision-making, fulfilling its role as an interpretive layer without requiring mode switches or navigation breaks.
The frontend realizes its interpretive role by coordinating several surfaces around the user’s changing focus. That focus is first established by the calendar views, which provide temporal overviews of available screenings, with runtime and venue encoded visually. The review dashboard then interprets this same scope evaluatively, contextualizing the calendar’s screenings within critical reception via side-by-side critic scores.
When review comparison prompts narrowing, film-level highlighting allows specific titles to be tracked across views, isolating their screenings in the calendar without breaking the frame of reference. Global filters operate at a broader level, constraining the overall scope by venue, runtime, or release type.
Together, these surfaces allow focus to narrow progressively without splintering across the interface, supporting exploration and decision-making as a single continuous process.