🎬 The Indie Cini
A data-driven planner for Chicago's independent cinemas.
Chicago is home to fantastic independent cinemas and many eager moviegoers. But these cinemas and moviegoers are often separated by a digital gulf, one largely unnoticed despite its expanse.
- Fandango and other major showtime aggregators tend not to list screenings from these venues.
- Critical reviews and aggregated scores are strewn across innumerable websites, making movie discovery needlessly difficult.
To address these gaps, The Indie Cini consolidates showtimes and film metadata from Chicago’s leading independent cinemas and enriches them with aggregated critic reviews. It currently covers the programming of the Gene Siskel Film Center, the Music Box Theatre, and FACETS.
Built on an end-to-end pipeline of scrapers, data modeling, and a tailored UI, The Indie Cini delivers an interactive calendar, a critic-score dashboard, flexible filters, and a responsive layout, all designed to simplify the discovery of Chicago's indie film culture.
🧭 Overview
The Indie Cini automates the collection, normalization, and transformation of cinema slate data from Chicago’s top independent venues, alongside film review data from a major aggregator. The result is a unified and consistently updated view of the city’s indie screening landscape.
Core outcomes include:
-
Unified dataset of all screening events across Chicago's major indie venues
-
Aggregated critic reviews powering a sortable, detail-rich dashboard
-
Interactive calendar interface, with filters that refine both the calendar and the review dashboard
-
Analytics-ready data foundation for analyzing score dynamics and theatrical longevity, with initial support for capturing user interaction events.
🏗️ Architecture
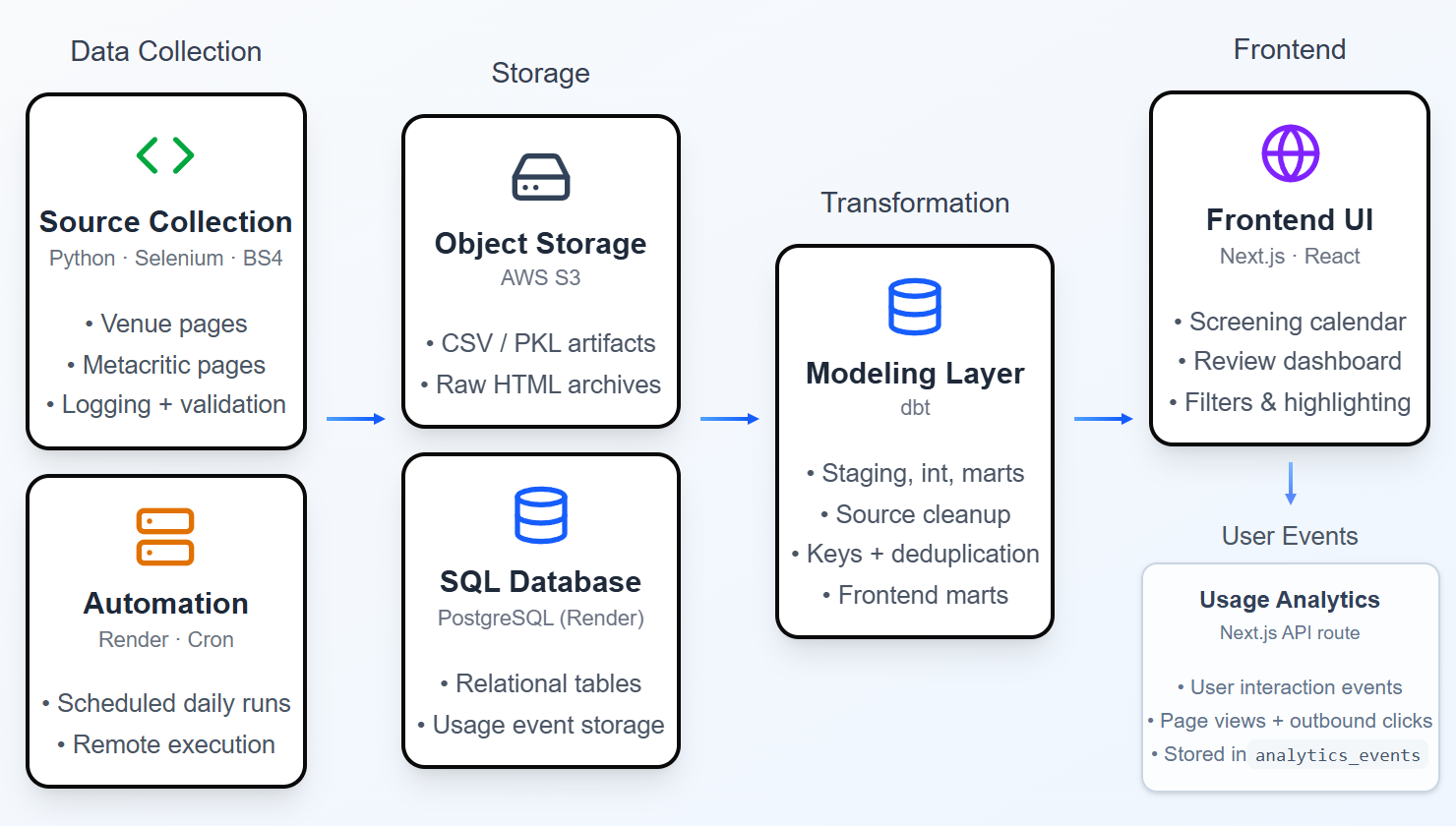
High-level architecture of The Indie Cini data pipeline (click to enlarge).
The system follows a modular ETL-style pipeline, built for stability and transparency:
-
Venue Scraping Layer (Python + Selenium + BeautifulSoup)
- Separate scrapers for Siskel, Music Box, and FACETS, with seasonal expansion support for CIFF
- Custom
RotatingDrivermanages rate limits, restarts, and JS-heavy pages ScrapeResultbundles parsed DataFrames, source HTML, and run metadata
-
Review Scraping Layer (Python + Selenium + BeautifulSoup)
- Metacritic pages identified via automated search with empirically tuned relevance ranking
- Dynamically loaded content retrieved through simulated user interaction (scrolling, “Load more," cookie dismissal)
- Master files (
mc_<data_type>_accum) reduce redundant scraping - (Planned): Letterboxd score integration
-
Artifact Observability Layer (Python + pandas)
- Timestamped inventory reports record the latest file, artifact date, and freshness status for each expected source/type combination
- Artifact quality reports produce summary metrics and entity-level findings for duplicate film identifiers, missing values, invalid runtimes or review scores, and unmatched Metacritic searches
- Reports are generated before database loading, creating a checkpoint between scrape artifact generation and downstream transformation
-
Ingestion Layer (Python + pandas + SQLAlchemy):
- Standardized loading routines clean column names and enforce dtypes
- Data is routed to either a local MySQL dev database or a production PostgreSQL database on Render
-
Storage Layer (PostgreSQL on Render, AWS S3)
- Unified
StorageBackendabstraction for consistent local/S3 file I/O pathing.pydefines centralized naming conventions and directory structureScrapeResultobjects serialize directly into versioned S3 archives
- Raw scrape artifacts persist in S3/local storage, while PostgreSQL houses the application's raw and transformed tables
- Unified
-
Transformation Layer (dbt)
- dbt transforms raw PostgreSQL tables into layered models spanning staging, intermediate, and mart tiers:
- Staging: Standardizes venue slate and review data
- Intermediate: Constructs stable join keys, deduplicates Metacritic records, and aggregates film reviews by publication and film
- Marts: Two feature-specific marts power the frontend:
mart_show_calendarandmart_review_dashboard
- dbt tests enforce core data integrity assumptions, including null, uniqueness, and composite-key checks.
- dbt transforms raw PostgreSQL tables into layered models spanning staging, intermediate, and mart tiers:
-
Frontend (Next.js + React Big Calendar)
- Interactive calendar with daily/weekly/agenda views
- Event blocks sized by runtime and color-coded by venue
- Tooltips preview event details and link directly to booking pages
- Critic-score dashboard with sorting, hovercards, and click-to-highlight behavior
- Filter controls for venue, release type, and runtime
- Fully responsive layout, plus a desktop resizable split panel between calendar and dashboard
-
Usage Analytics (Next.js API routes + PostgreSQL)
- Lightweight frontend instrumentation captures user interaction events, including page views and outbound clicks
- Events are sent via a server-side API route and persisted to an append-only
analytics_eventstable in PostgreSQL - A dbt staging model (
stg_analytics_events) standardizes this data for potential downstream analysis - This layer establishes a foundation for future behavioral insights, without being a core feature of the current application
🧩 Key Features
| Category | Feature |
|---|---|
| Data Integration | Unified cinema slate and review datasets spanning Chicago's leading independent cinemas |
| Transformation & Modeling | Layered dbt architecture (staging → intermediate → marts) with surrogate key construction, deduplication pipelines, and feature-specific data marts |
| Automation | Automated daily web scraping and ingestion via a custom rotating Selenium WebDriver, orchestrated via Render cron jobs |
| Data Quality & Observability | Artifact inventory reports track scrape freshness, while quality reports run structural checks and record entity-level findings; ingestion checks, structured logging, and dbt tests further enforce consistency |
| Storage Architecture | Centralized storage abstractions standardize file and object I/O, with PostgreSQL serving as the canonical warehouse for ingested and modeled data |
| Frontend | Interactive screening calendar and review dashboard with dynamic filtering, tooltips, and responsive layout |
| User Analytics | Lightweight tracking of user interaction events (page views, outbound clicks) via a custom API route, with events stored in PostgreSQL and standardized in dbt for potential downstream analysis |
🗂️ Data Sources
| Source | Purpose |
|---|---|
| Gene Siskel Film Center | Primary showtime data and film metadata |
| Music Box Theatre | Primary showtime data and film metadata |
| FACETS | Primary showtime data and film metadata |
| Chicago International Film Festival (CIFF) | Seasonal expansion of the above sources |
| Metacritic | Aggregated critic reviews and associated film metadata |
| Letterboxd (in development) | Audience score enrichment |
🧮 Technologies Used
| Layer | Stack |
|---|---|
| Backend & Ingestion | Python, Selenium, BeautifulSoup, pandas, SQLAlchemy |
| Storage | PostgreSQL (Render), AWS S3 |
| Transformation | dbt |
| Frontend | Next.js / React, React Big Calendar, TailwindCSS |
| Deployment & Orchestration | Render (Web Service + Cron jobs) |
| Logging & Observability | Custom structured logger; artifact inventory and quality reports |
| Version Control | Git / GitHub (private repository) |
🧰 Development Notes
- Environment: Linux-based development with ChromeDriver for Selenium
- Storage Structure:
data/andtest/directories mirror production vs. sandbox runs - Output Format: CSV and PKL scrape outputs archived under
/data/pkl/{venue or review source}/{category}/ - Observability Outputs: Timestamped inventory and quality reports are archived under
/data/pkl/observability/ - Logging: Timestamped, structured logs (e.g.,
facets_scrape | +0.01s | https://facets.org/...)
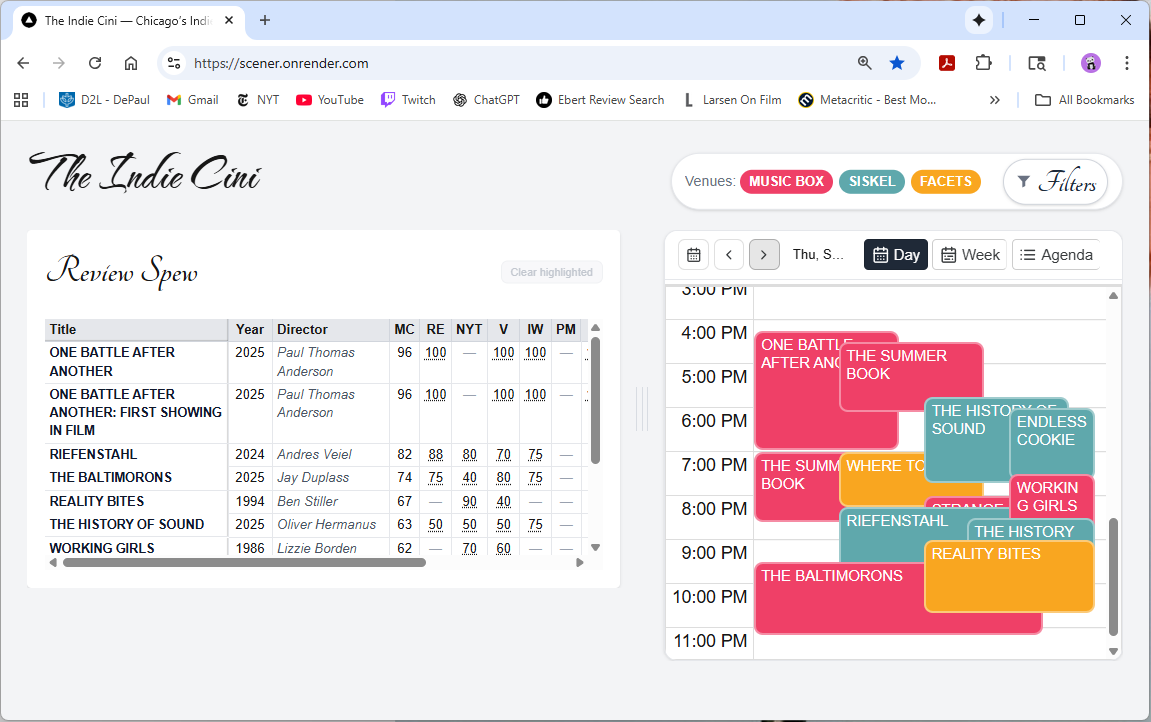
📸 Showcase
Live Demo
- Shortlink: bit.ly/indiecini
- Direct: scener.onrender.com
Visual Highlights
- 📅 Main Calendar: Weekly and agenda views with color-coded venues
- 🔍 Filters Panel: Filter by release type, runtime, and venue
- 🗞️ ReviewSpew Dashboard: Sortable critic-review table with hovercards
- 🎯 Click-to-Highlight: Selecting a film or director isolates its screenings in the calendar
- 🖥️ Resizable Split-Panel Layout: Drag to adjust the space between the ReviewSpew dashboard and the calendar.
- 📱 Responsive Mobile Layout
- 🧩 Architecture Diagram: ETL pipeline overview → scener.onrender.com/pipeline
🚀 Future Work
- Integrate Letterboxd and Rotten Tomatoes audience scores
- Add a scrollable film-poster ribbon beneath the ReviewSpew dashboard for quick visual browsing.
- Implement predictive models for audience–critic divergence and for the duration of a film's theatrical run.
- Expand to additional Chicago-area venues: Logan Square, Davis, ... chain cinemas (possibly).
Frontend-specific
- Add filters for review scores, specified date ranges, and polarizing genres.
- Surface subtle features (like click-to-highlight) through small UX cues.
👤 Author
Max Ruther
M.S. Computer Science (Data Science concentration) — DePaul University
Solo developer and data engineer behind The Indie Cini.
💌 Portfolio
This repository remains private to protect proprietary logic and sensitive API configurations.
Public assets, screenshots, and diagrams are available on the case-study page.